
用過 Claude Sonnet 4.5 的龍蝦 OpenClaw 再回頭看便宜模型:OpenRouter 多模型實測心得
TL;DR: 我原本用 Claude Sonnet 4.5 搭配 OpenClaw 做日常 AI 助理,品質很好但成本不低。透過 OpenRouter 嘗試了一輪便宜模型之後,得到一個很誠實的結論:便宜的模型表面上省錢,實際上是在浪費你的時間。但也不是完全沒有驚喜,Grok 4.1 Fast 目前是我覺得 CP 值算高的選擇。以下是我的實測心得。
為什麼開始探索其他模型
先講背景。我之前一直用 Claude Sonnet 4.5 搭配 OpenClaw 和 Telegram 做日常的 AI 助理,用來處理摘要、翻譯、資料整理這些瑣事。體驗很好,回覆品質穩定,很多事情丟過去就能一次到位,幾乎不需要我反覆引導。
問題是,Sonnet 4.5 的價格擺在那裡:輸入 $3、輸出 $15(每百萬 token),在 OpenRouter 的分級裡直接被歸類為 Premium。如果你每天大量使用,帳單累積起來是有感的。
所以我開始好奇:市面上那些便宜五倍、十倍的模型,到底能不能用?是真的划算,還是只是便宜沒好貨?
帶著這個問題,我在 OpenRouter 上開始了一輪模型探索。我挑模型的方式也很簡單:先看 OpenRouter 上排名前幾的模型,再參考一張社群整理的模型試算表(裡面列了各模型的價格、context window、支援的 modality、成本等級等資訊。原本還想找速度,但找不到。),從不同等級裡各挑幾個出來實測。如果你也想自己試,這張表很值得參考,可以從裡面按照自己的預算和需求挑模型來測。
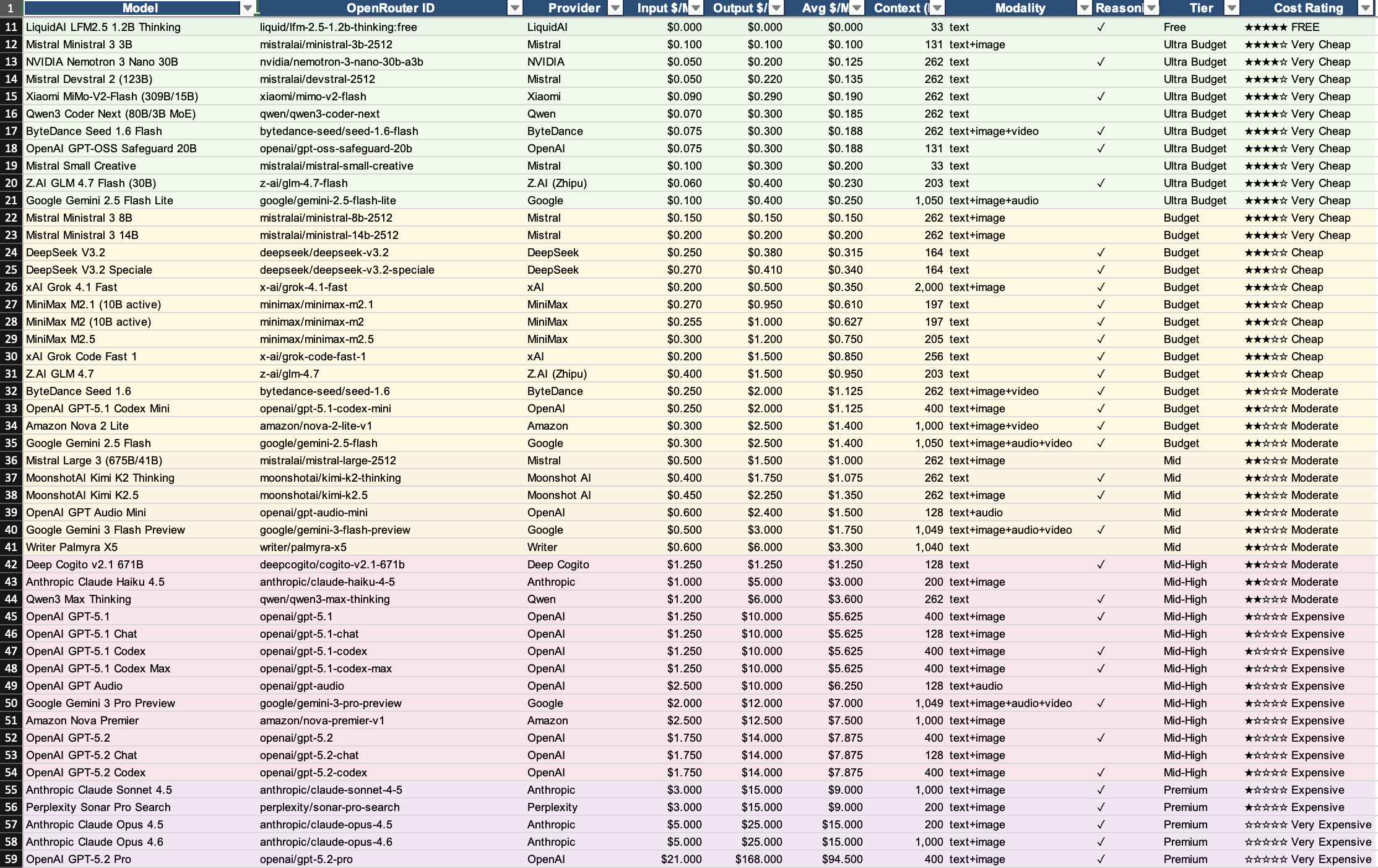
我怎麼評估這些模型
先講一下我的評估方式,這不是什麼嚴謹的 benchmark 測試,就是某天晚上花了幾個小時,把幾個模型輪流接上 OpenClaw 實際跑一輪的體感。我測試的任務都是我平常會用到的:每日任務處理、推特文章摘要、規劃搜集資料、還有分派工作給子代理(Subagent)。全程沒有測寫程式碼的部分,純粹是日常助理和任務調度的場景。
聰明程度: 能不能理解複雜的指令、能不能舉一反三、會不會自己延伸思考,還是每個步驟都要我手把手帶。
回覆速度: 日常助理場景,速度很重要。如果一個模型很聰明但要等三十秒才回覆,那跟自己做差不多。
回覆品質: 內容夠不夠充實、有沒有料、語言流暢度如何。
回覆態度和內容量: 這個很微妙但很重要。笨的模型回覆看起來好像有回答你,但仔細看什麼都沒幫到。更慘的是動不動就雙手一攤跟你說「我無法完成這個任務」。這跟笨服務生一樣,你問他什麼他只會說「不好意思、我不行、我們沒有」,句號,沒了。聰明的模型就算真的做不到,它會跟你解釋為什麼不行、目前的限制是什麼、有沒有替代方案可以試。光是這個差異,就能讓你感受到模型的「智商」是否在線。
回傳格式的適應能力: 我的使用場景是 Telegram,這代表模型回傳的格式很關鍵。有些模型很愛用 Markdown 表格、程式碼區塊這些東西,在網頁上看很漂亮,但丟到 Telegram 裡排版就整個炸開,根本沒辦法看。最讓人抓狂的是你明明跟它講了「不要用表格格式」,它下一則回覆照樣給你一個表格,講不聽。好的模型你提醒一次,它後續就會自動調整輸出格式,這種「聽得懂人話」的能力其實也是聰明程度的一部分。
需不需要反覆引導: 這是我覺得最關鍵的指標。頂級模型你給一個大方向它就能自己跑,便宜模型你得一步一步帶,光是引導花的時間就把省下來的錢全部吃回去。
基準線就是 Claude Sonnet 4.5 的使用體驗。以下所有比較都是跟它對照。但我也是看了這個表格之後才發現 Sonnet 4.5 在最下面的 Premium,有夠淒慘,因為已經習慣了這麼高級的模型,原本想說 Sonnet 應該還好沒有很強吧。
各模型實測心得
Gemini 2.5 Flash Lite($0.10 / $0.40):便宜到底,但笨到底
先從最便宜的開始講。Google 的 Gemini 2.5 Flash Lite,輸入 $0.10、輸出 $0.40,在 OpenRouter 上被歸類為 Ultra Budget,價格確實很香。
但用了之後我只有一個感想:你得到的就是你付出的。
連最基本的文章摘要都做得磕磕絆絆,速度是算快,但最讓我受不了的是完全不會舉一反三,你給它一個任務,它就只做那一個任務,不會自己延伸、不會主動補充相關資訊。每一步都需要你明確指示,像在教一個完全沒有經驗的實習生。
而且它的回覆量少得可憐,看起來好像有回答你的問題,但仔細看就是兩三句話帶過,什麼具體的東西都沒有。你問它整理一份資料,它給你的結果就像考試寫了名字但交白卷。碰到稍微困難的任務就直接跟你說做不到,連嘗試都不嘗試,更別提給你替代方案了。
如果你的需求真的只是最簡單的文字處理,勉強可以用。但只要稍微複雜一點的任務,省的那幾毛錢完全不值得你花的時間。
MiniMax M2.5($0.30 / $1.20):Benchmark 好看,實際偏笨
MiniMax 的 M2.5 是一個蠻有趣的案例。如果你只看跑分,這個模型的數據其實不差,價格也算 Budget 等級。
但實際對話下來,說真的,還是有點太笨了。理解能力不夠,回覆經常答非所問,複雜一點的指令就開始出包。格式方面也讓人頭痛,我在 Telegram 上用,跟它說過不要用 Markdown 表格,它照樣每次都丟表格出來,排版在 Telegram 上炸得一塌糊塗。講了三次還是講不聽,這種「無法遵守指令」的問題在便宜模型上特別明顯。
我後來想想,也許是因為 MiniMax M2.5 在 coding benchmark 上的表現特別強,所以跑分好看,但平常的推理能力和日常任務處理這塊並沒有特別優化。說白了就是偏科,寫程式可能可以,但我這次測的全部都是日常助理的任務,一行 code 都沒寫,所以它的強項完全沒派上用場。
這讓我學到一件事:Benchmark 分數跟實際使用體驗之間,存在一條巨大的鴻溝。跑分高不代表好用,尤其在日常對話和任務處理的場景。
DeepSeek V3.2($0.25 / $0.38):聰明但太慢
DeepSeek V3.2 是這輪測試裡讓我最糾結的模型。
聰明程度確實可以,我覺得已經接近 Sonnet 4.5 的水準了。理解力好、回覆有深度、能自己延伸思考。價格也漂亮,輸入 $0.25、輸出 $0.38,被歸在 Budget 等級。
但問題出在速度。回覆速度實在太慢了,慢到讓我覺得「我等它回覆的時間,都夠我自己做完了」。在日常助理的場景裡,速度是很關鍵的。你不會想每次問一個問題就等半天。
說白了,DeepSeek V3.2 的聰明程度被它的速度拖累了。等待的時間成本直接抵消了它的價格優勢。如果哪天它的速度能提上來,會是一個非常有競爭力的選擇。但現階段,做為日常助理來用,體驗不夠流暢。
Claude Haiku 4.5($1.00 / $5.00):自家的輕量版,但⋯⋯
身為 Claude 的長期用戶,我當然也試了 Anthropic 自家的輕量版 Haiku 4.5。價格是 Mid-High 等級,輸入 $1、輸出 $5。
老實說,用過之後有點失望。名字叫 Haiku,果然就是「輕量」的意思,不只是體積輕量,腦子也有點輕量。跟 Sonnet 4.5 比起來,差距太明顯了。很多任務它處理得不夠到位,還是需要反覆引導才能得到我要的結果。
而且以它的價格來說,性價比也不算特別好。你付了 Budget 以上的錢,得到的卻是 Budget 等級的表現,這就尷尬了。
Grok 4.1 Fast($0.20 / $0.50):目前的驚喜
最後要講的是 xAI 的 Grok 4.1 Fast,這個模型是我這輪測試裡最大的驚喜。
先看帳面數據:輸入 $0.20、輸出 $0.50,被歸在 Budget 等級。Context window 高達 2,000K(200 萬 token),這個數字非常誇張,市面上很少模型能給到這麼大的上下文視窗。支援 text+image 輸入。
實際使用體驗呢?回覆速度快,名字裡的「Fast」是真的。回覆內容充實、有料,不是那種敷衍了事的短回覆。理解能力也還算可以,雖然沒有到 Sonnet 4.5 或 DeepSeek V3.2 的水準,但以這個價格來說,已經超出我的預期了。
更重要的是,它不需要我每一步都手把手引導。給一個方向,它能自己往前跑一段,雖然偶爾會跑偏,但整體效率比其他 Budget 模型好很多。碰到做不到的事情,它也會好好跟你解釋為什麼,然後主動提供替代做法,這點讓我蠻意外的。格式方面也比較聽話,提醒過一次之後,後續的回覆就會自動調整,不會一直重複犯同樣的錯。
如果你正在找一個便宜、快、堪用的日常模型,Grok 4.1 Fast 是我目前會推薦的第一選擇。
關鍵發現:便宜模型的隱藏成本
經過這一輪測試,我最大的體悟是:便宜模型的真正成本不在 API 帳單上,在你的時間上。
用 Sonnet 4.5 的時候,我丟一個任務過去,它回覆的結果八九成可以直接用。但換成 Budget 模型之後,每個任務都變成了一場拉鋸戰。回覆品質不到位,你要追問;理解錯誤,你要重新解釋;少做了一個步驟,你要補充指令。一來一回,花掉的時間遠超過你以為省下的錢。
我之前用 Sonnet 4.5 用得很順,什麼事情丟過去都能做好,結果就是把胃口養壞了。當你習慣了頂級模型一次到位的效率,再回頭用便宜模型,那個落差感真的很大。
所以你真正該問的問題只有一個:「我的一個小時值多少錢?」如果你是開發者、是創作者、是任何用時間換錢的人,請認真算這筆帳。用便宜模型省下的 API 費用,可能還不到你多花的時間值的十分之一。
我的模型分層策略(暫定)
基於目前的測試結果,我暫時是這樣分配的:
日常快速回覆: Grok 4.1 Fast。速度快、價格低、品質堪用,適合處理不需要太高智商的日常任務。
需要深度思考的任務: 看情況切回 Sonnet 4.5,或者等 DeepSeek V3.2 速度改善後再考慮。有些任務就是需要聰明的腦子,這上面不能省。
最頂級的任務: Claude Sonnet 4.5,甚至 Opus。寫長文、做複雜分析、處理需要高度理解力的工作,頂級模型的品質差距在這些場景最明顯。
核心邏輯就是:用任務的重要程度來決定用哪個等級的模型,而不是一刀切只用最便宜或最貴的。
給同樣在找替代方案的人的建議
如果你也在考慮從頂級模型往下探索便宜的替代方案,以下是我的幾個建議:
第一,先想清楚你的時間值多少錢。 這是所有決策的起點。如果你的時間很值錢,省 API 費用的同時浪費大量時間來引導模型,是一筆虧本的買賣。
第二,Benchmark 分數不等於實際使用體驗。 MiniMax M2.5 的跑分看起來不錯,但實際用起來跟頂級模型差很遠。別被數字騙了,自己試過才知道。
第三,不要期待一個模型通吃所有場景。 這是我目前最大的心得。不同等級的模型適合不同的任務,學會分層使用才是最有效率的策略。
第四,如果只能試一個,先試 Grok 4.1 Fast。 以 Budget 等級來說,它目前是我測過最均衡的選項。速度、價格、品質三個維度都有一定水準。
我還在持續測試更多模型,之後有新的發現會再更新。對了,已經有大神問我 Qwen3 Coder Next 測過了沒,還有最近剛推出自家 Claw 的 MoonshotAI Kimi K2.5 我也還沒試。下一步可能會接著測測看這兩個,目前就先用 Sonnet 4.5 跟 Grok 4.1 Fast 撐著,等有新心得再來更新。
推薦閱讀



喜歡這篇文章嗎?
訂閱電子報,每週收到精選技術文章與產業洞察,直送你的信箱。
💌 隨時可以取消訂閱,不會收到垃圾郵件